Construa um Assistente de IA para SAP em 7 Passos (Guia 2026)
Automatize perguntas sobre o sistema SAP com um assistente de IA em Python. Aumente a eficiência, reduza tickets de suporte e capacite utilizadores. Aprenda a construí-lo agora!

Atualizado em abril de 2026 com os preços e funcionalidades mais recentes.
O Que Você Vai Conquistar: Transformando o Suporte SAP com IA
Imagine seus usuários finais SAP obtendo respostas instantâneas e precisas para suas perguntas sobre o sistema, sem precisar abrir um chamado ou esperar pelo suporte de TI. Isso não é uma fantasia futurista; é a realidade imediata que você pode criar ao construir um Assistente de IA para o Sistema SAP. Como proprietário de processo, seu objetivo principal é eficiência, precisão e autonomia do usuário – e essa solução entrega exatamente isso. Estamos falando de uma mudança mensurável de um combate a incêndios reativo para um suporte proativo e de autoatendimento.
Considere as frustrações diárias: "Qual o status do Pedido de Compra 4500001234?" "Como faço para reverter uma entrada de mercadoria no MIGO?" "Qual relatório me mostra os pedidos de venda em aberto para a região EMEA-Norte?" Esses não são problemas complexos, mas o tempo cumulativo gasto para encontrar respostas, ou esperar por um colega, drena a produtividade em toda a sua organização. Nosso objetivo é eliminar esse atrito.
Os benefícios tangíveis para o seu negócio são profundos:
- Redução do Esforço Manual: Reduza drasticamente os chamados de suporte para dúvidas comuns, liberando seus especialistas funcionais e equipe de TI para trabalhos mais estratégicos. Já vi organizações reduzirem as consultas de suporte de Nível 1 em até 40% nos primeiros seis meses de implantação de um assistente como este.
- Respostas Mais Rápidas e Precisas: A IA não se cansa nem esquece. Ela recupera informações do seu sistema SAP e da documentação instantaneamente, garantindo consistência e precisão. Isso significa menos erros decorrentes de instruções desatualizadas ou mal interpretadas.
- Usuários Finais Empoderados: Dê aos seus usuários de negócio as ferramentas para se ajudarem. Isso promove uma cultura de autossuficiência e reduz a dependência das equipes de suporte central, levando a maior satisfação no trabalho e produtividade.
- Melhora na Precisão dos Dados: Ao guiar os usuários para processos corretos e pontos de entrada de dados, o assistente de IA pode contribuir indiretamente para dados mais limpos dentro do seu sistema SAP, reduzindo os esforços de conciliação posteriores.
- ROI Mensurável na Automação: A economia de custos com a redução de chamados de suporte, resolução mais rápida de problemas e aumento da produtividade do usuário justificam rapidamente o investimento. Pense no custo total de um único chamado de suporte – multiplique isso por centenas ou milhares por mês, e o ROI se torna convincente.
Essa iniciativa move sua organização de um modelo de suporte reativo, onde os problemas são corrigidos após ocorrerem, para um modelo proativo, onde os usuários são guiados ao sucesso antes mesmo que os problemas surjam. Trata-se de colocar o poder da sua base de conhecimento SAP diretamente nas mãos de quem mais precisa, 24 horas por dia, 7 dias por semana.
Antes de Começar: Pré-requisitos Essenciais para Seu Assistente de IA SAP
Embarcar nesta jornada exige uma base sólida. Antes de escrever uma única linha de código ou configurar um modelo de IA, certifique-se de que esses pré-requisitos estejam em vigor. Negligenciar qualquer um deles pode levar a obstáculos significativos e atrasos no projeto.
- Acesso a um Sistema SAP: Isso é inegociável. Você precisará de acesso a um sistema SAP operacional (por exemplo, S/4HANA, ECC, SAP BW, SuccessFactors, etc.) com as permissões de leitura necessárias para os dados que você pretende consultar. Comece com um sistema de desenvolvimento ou garantia de qualidade para minimizar o impacto na produção. Certifique-se de ter as contas de usuário e funções apropriadas configuradas para extração de dados.
- Proficiência Básica em Python: Embora você não precise ser um guru em Python, um entendimento fundamental da sintaxe, estruturas de dados e uso de bibliotecas Python é essencial. Se sua equipe não tiver isso, considere aprimorar as habilidades ou delegar a um desenvolvedor Python. Lembre-se, não se trata apenas de scripting; trata-se de construir uma aplicação.
- Uma Conta em Plataforma de IA/ML: Você precisará de acesso a um provedor de Large Language Model (LLM). As opções populares incluem OpenAI (para GPT-3.5, GPT-4), Google Cloud AI (para Gemini) ou Azure AI (para serviços OpenAI). Configure uma conta, entenda suas políticas de uso de API e proteja suas chaves de API. Alguns provedores oferecem camadas gratuitas ou créditos para experimentação inicial.
- Um Entendimento Claro das Perguntas/Pontos de Dor Comuns do SAP: É aqui que o proprietário do processo de negócio realmente se destaca. Você precisa saber com quais perguntas seus usuários finais mais se debatem. Quais são os gargalos? Quais transações causam confusão? Sem essa percepção, seu assistente de IA estará resolvendo problemas que ninguém tem.
- Acesso à Rede do Seu Ambiente Python ao SAP: Sua aplicação Python precisa se comunicar com o SAP. Isso geralmente envolve serviços RFC (Remote Function Call) ou OData. Certifique-se de que sua configuração de rede permita essa comunicação, incluindo regras de firewall e configurações de proxy, se aplicável.
- Plano de Considerações de Privacidade e Segurança de Dados: Isso não pode ser uma reflexão tardia. Você estará lidando com dados SAP potencialmente sensíveis. Como você protegerá as credenciais? Que dados o assistente de IA pode acessar? Como você lidará com a retenção e anonimização de dados? Um plano claro, em colaboração com suas equipes de segurança e conformidade, é fundamental. GDPR, CCPA e outras regulamentações se aplicam.
De uma perspectiva estratégica, ter uma equipe pequena e dedicada com conhecimento funcional de SAP e habilidades de desenvolvimento Python/IA acelerará significativamente seu progresso. Não tente construir isso isoladamente.
Passo 1: Definindo o Escopo e a Base de Conhecimento do Seu Assistente de IA SAP
O maior erro que vi em projetos de IA é tentar abraçar o mundo. Para seu assistente de IA SAP, a especificidade é sua amiga. Você precisa definir um escopo estreito e de alto valor para a iteração inicial. Não tente responder a todas as perguntas possíveis do SAP desde o primeiro dia.
Comece identificando módulos SAP específicos e tipos de perguntas. Por exemplo:
- SAP FI (Contabilidade Financeira): "Qual é o saldo da conta contábil X?" "Como faço para lançar uma fatura de fornecedor?"
- SAP CO (Controle): "Qual é o centro de custo do departamento Y?" "Como faço para executar um relatório de elemento de custo?"
- SAP SD (Vendas e Distribuição): "Qual o status do Pedido de Venda Z?" "Como faço para criar um novo registro mestre de cliente?"
- SAP MM (Gestão de Materiais): "Onde o material A está armazenado?" "Como faço para realizar uma entrada de mercadoria para o Pedido de Compra B?"
Recomendo criar um "domínio de conhecimento" para sua primeira versão. Digamos que você escolha "Consultas de Status de Pedido de Compra" dentro do SAP MM. Isso significa que seu assistente se concentrará exclusivamente em perguntas relacionadas a números de PO, seu status atual, datas de entrega, informações do fornecedor, etc. Essa abordagem focada permite construir, testar e refinar rapidamente.
Para coletar essas perguntas específicas, conduza entrevistas curtas e direcionadas com usuários finais no módulo escolhido. Pergunte a eles:
"Quais são as 3-5 perguntas mais comuns que você faz sobre Pedidos de Compra todos os dias?"
"Que informações você geralmente precisa ao verificar o status de um PO?"
"Quais são os maiores pontos de dor ou perda de tempo ao lidar com POs?"
Documente essas perguntas e suas respostas esperadas. Isso formará os dados de treinamento iniciais e os cenários de teste para seu assistente. Lembre-se, comece pequeno, alcance o sucesso, depois itere e expanda.
Passo 2: Conectando Python ao Seu Sistema SAP para Extração de Dados
É aqui que a teoria encontra a prática. Sua aplicação Python precisa de uma maneira segura e eficiente de extrair dados do SAP. Existem vários métodos bons, cada um com suas próprias vantagens.
Métodos para Conectar Python ao SAP:
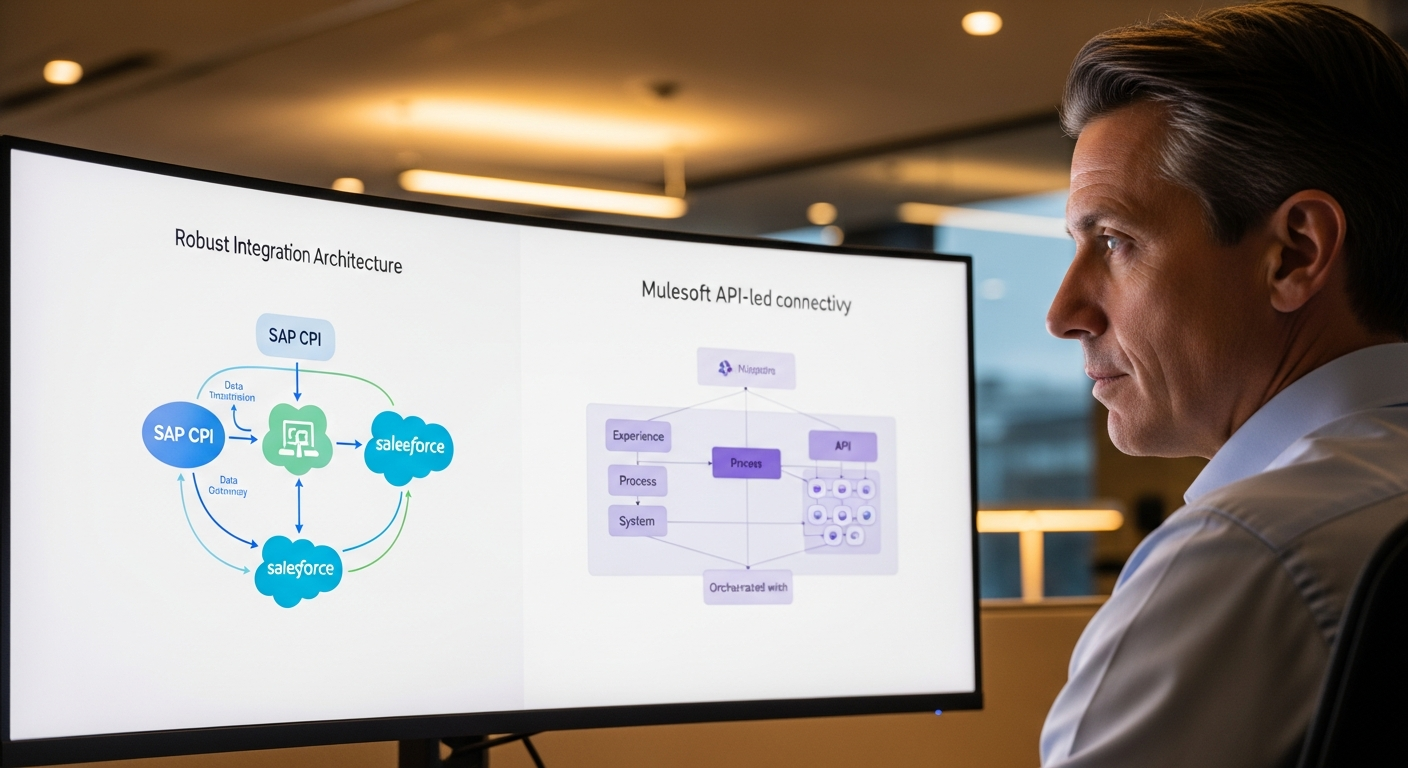
- SAP RFC (Remote Function Call) usando PyRFC: Este é frequentemente o método mais direto e poderoso para interagir com a lógica central do SAP. PyRFC é um binding Python para a biblioteca NetWeaver RFC do SAP. Ele permite que você chame BAPIs (Business Application Programming Interfaces) e módulos de função personalizados habilitados para RFC diretamente do Python.
from pyrfc import Connection # Connection parameters - replace with your actual details params = { "ashost": "seu_host_sap", "sysnr": "00", # SAP System Number "client": "100", # SAP Client "user": "seu_usuario_sap", "passwd": "sua_senha_sap", "lang": "PT" # Ou "EN" se preferir a interface em inglês } try: connection = Connection(**params) print("Conectado ao SAP com sucesso!") # Exemplo: Chamar uma BAPI simples para obter informações do sistema result = connection.call("BAPI_SYSTEM_GETSTATUS") print(f"Nome do Sistema SAP: {result['SYSTEM']['SAP_SYSTEM']}") print(f"Release do SAP: {result['SYSTEM']['SAP_RELEASE']}") except Exception as e: print(f"Erro ao conectar ao SAP: {e}") finally: if 'connection' in locals() and connection: connection.close() print("Conexão encerrada.")Nota de Segurança: Nunca codifique credenciais em código de produção. Use variáveis de ambiente, cofres seguros (como AWS Secrets Manager, Azure Key Vault) ou o SAP Secure Store para credenciais.
- Serviços SAP OData (usando a biblioteca
requestsdo Python): OData (Open Data Protocol) fornece uma maneira padronizada de criar e consumir APIs REST. Muitas aplicações SAP modernas (S/4HANA, apps Fiori) expõem dados via OData. Isso é excelente para consumir dados, mas geralmente não para executar lógica de negócio complexa.import requests from requests.auth import HTTPBasicAuth # OData service URL - replace with your actual service endpoint odata_url = "https://seu_host_sap:porta/sap/opu/odata/sap/SD_SALESORDER_SRV/SalesOrderCollection?$top=10" username = "seu_usuario_sap" password = "sua_senha_sap" try: response = requests.get(odata_url, auth=HTTPBasicAuth(username, password)) response.raise_for_status() # Raise an HTTPError for bad responses (4xx or 5xx) data = response.json() print("OData obtido com sucesso!") # print(data['d']['results']) # Accessing the actual data except requests.exceptions.RequestException as e: print(f"Erro ao obter OData: {e}") - SAP BAPIs/IDocs (via RFC): Como mencionado, BAPIs são frequentemente chamadas via RFC. IDocs (Intermediate Documents) são para comunicação assíncrona, tipicamente processados através do gateway do SAP. Embora o PyRFC possa acionar o processamento de IDocs, o consumo direto de IDocs para consulta em tempo real por um assistente de IA é menos comum do que o uso de BAPIs ou OData.
- Conexão Direta ao Banco de Dados: Embora tecnicamente possível (por exemplo, conectar a um banco de dados HANA via SQLAlchemy), isso geralmente é desencorajado para um assistente de IA. Ele ignora a segurança da camada de aplicação do SAP e a lógica de negócios, levando a potenciais problemas de integridade de dados e vulnerabilidades de segurança. Mantenha-se nas APIs fornecidas pelo SAP.
Para seu assistente inicial de "Status do Pedido de Compra", você pode usar uma BAPI como `BAPI_PO_GETDETAIL` via PyRFC, ou um serviço OData que exponha dados de pedidos de compra, se disponível em seu sistema S/4HANA. Priorize a segurança e use o usuário com o menor privilégio necessário para a extração de dados.
Passo 3: Preparando Dados SAP para Consumo por IA (Vetorização e Indexação)
Dados SAP brutos, sejam entradas de tabela, códigos de transação ou documentação personalizada, não são diretamente compreendidos por Large Language Models (LLMs). Precisamos transformá-los em um formato que a IA possa processar eficazmente. É aqui que o embedding de texto e os bancos de dados vetoriais entram em jogo.
Embedding de Texto: Este processo converte texto legível por humanos (por exemplo, "O status do Pedido de Compra 4500001234 está aguardando aprovação") em vetores numéricos (listas de números de ponto flutuante). Crucialmente, esses vetores capturam o significado semântico do texto. Frases com significados semelhantes terão vetores numericamente "próximos" uns dos outros em um espaço multidimensional. Usamos modelos pré-treinados, frequentemente da biblioteca sentence-transformers ou modelos de embedding da OpenAI, para isso. Por exemplo:
from sentence_transformers import SentenceTransformer
import numpy as np
# Carrega um modelo de transformador de sentença pré-treinado
model = SentenceTransformer('all-MiniLM-L6-v2')
# Exemplo de frases relacionadas ao SAP
sap_sentences = [
"Como verifico o status de um pedido de compra?",
"Qual é o estado atual do PO 4500001234?",
"Crie um novo pedido de venda na VA01.",
"Qual é o processo para criar um pedido de venda?",
"A capital da França é Paris." # Frase irrelevante
]
# Gera embeddings para as frases
sentence_embeddings = model.encode(sap_sentences)
print("Embeddings gerados. Shape:", sentence_embeddings.shape)
# print(sentence_embeddings[0][:5]) # Imprime as 5 primeiras dimensões do primeiro embedding
# Você pode então calcular a similaridade (por exemplo, similaridade de cosseno)
# para ver o quão próximos os significados são.
# Por exemplo, as duas primeiras frases devem ter alta similaridade.
# A última frase deve ter baixa similaridade com as perguntas do SAP.
Bancos de Dados Vetoriais (Vector Stores): Uma vez que você tenha esses embeddings numéricos, você precisa de uma maneira de armazená-los e recuperá-los eficientemente. Esse é o propósito de um banco de dados vetorial. Quando um usuário faz uma pergunta, você primeiro converterá sua consulta em um embedding. Em seguida, você usará o banco de dados vetorial para encontrar os "pedaços" de dados ou documentação SAP "mais semelhantes" (mais próximos no espaço vetorial). Esse processo é chamado de busca semântica.
Os armazenamentos vetoriais populares incluem Pinecone, Weaviate, ChromaDB e Milvus. Para um projeto inicial menor, o ChromaDB pode ser executado localmente e é bastante fácil de usar. Esses bancos de dados são otimizados para buscas de similaridade em um grande número de vetores.
- Extrair Dados SAP: Puxe dados relevantes (por exemplo, detalhes de PO, descrições de transações, documentação de módulo funcional, guias de processo personalizados) do SAP usando os métodos do Passo 2.
- Chunking (Divisão em Pedaços): Divida documentos ou conjuntos de dados grandes em "pedaços" menores e gerenciáveis (por exemplo, 200-500 palavras). Isso ajuda a IA a se concentrar em informações específicas.
- Embed Chunks: Converta cada pedaço em seu embedding vetorial usando o modelo escolhido.
- Indexar no Vector Store: Armazene esses embeddings (juntamente com seu conteúdo de texto original) em seu banco de dados vetorial.
Este passo de pré-processamento é crucial para o padrão "Retrieval Augmented Generation" (RAG), que discutiremos a seguir. Sem ele, seu LLM não teria contexto sobre seu sistema SAP específico ou documentação.
Passo 4: Integrando Large Language Models (LLMs) para Compreensão da Linguagem Natural
Agora que seus dados SAP estão vetorizados e indexados, é hora de trazer o cérebro da operação: o Large Language Model. O LLM é responsável por entender a consulta em linguagem natural do usuário e gerar uma resposta coerente e relevante.
Escolhendo um LLM:
Vários LLMs poderosos estão disponíveis via APIs:
- OpenAI: GPT-3.5 Turbo e GPT-4 são líderes da indústria, conhecidos por suas fortes capacidades de raciocínio e geração. O GPT-4 é mais poderoso, mas também mais caro.
- Anthropic: Claude (por exemplo, Claude 3 Opus, Sonnet, Haiku) oferece desempenho competitivo, muitas vezes com foco em segurança e janelas de contexto mais longas.
- Google Cloud AI: Os modelos Gemini (Pro, Ultra) são as últimas ofertas do Google, fornecendo fortes capacidades multimodais e de raciocínio.
- Azure AI: Fornece acesso a modelos OpenAI dentro do ecossistema Azure, oferecendo recursos de segurança e conformidade de nível empresarial.
Honestamente, para a maioria dos assistentes de IA SAP iniciais, o GPT-3.5 Turbo ou um modelo comparável oferece um excelente equilíbrio entre desempenho e custo.
Engenharia de Prompt: Guiando a IA
A engenharia de prompt é a arte e a ciência de criar instruções e contexto eficazes para o LLM. Um bom prompt guia a IA para gerar a saída desejada. Para seu assistente SAP, os prompts geralmente incluirão:
- Papel do Sistema: Defina a persona da IA (por exemplo, "Você é um consultor SAP MM especialista.").
- Consulta do Usuário: A pergunta real do usuário final.
- Contexto Recuperado: Os pedaços de dados SAP relevantes recuperados do seu banco de dados vetorial (esta é a parte RAG!).
- Instruções: Regras específicas para a IA (por exemplo, "Use apenas o contexto fornecido. Se a resposta não estiver no contexto, declare que você não sabe.").
Exemplo de Prompt para uma Pergunta SAP (usando RAG):
# Assume 'user_query' é "Qual é o status do PO 4500001234?"
# Assume 'retrieved_sap_context' contém dados relevantes do seu vector store, por exemplo:
# "O Pedido de Compra 4500001234 foi criado em 26/10/2025 por João Silva. Status atual: Aguardando Aprovação do Gerente Silva. Data de entrega prevista: 15/11/2025. Fornecedor: Global Supplies Inc."
# "A transação ME23N é usada para exibir pedidos de compra."
llm_prompt = f"""
Você é um consultor SAP de Gestão de Materiais (MM) especialista. Sua tarefa é responder a perguntas sobre dados do sistema SAP.
Aqui estão as informações SAP relevantes que você deve usar como contexto:
---
{retrieved_sap_context}
---
Com base APENAS no contexto fornecido, responda à seguinte pergunta:
"{user_query}"
Se a resposta não puder ser encontrada no contexto fornecido, por favor, responda com: "Desculpe, não consegui encontrar essa informação nos dados SAP disponíveis."
"""
# Então você enviaria este llm_prompt para a API do LLM escolhido.
# Por exemplo, usando o cliente Python da OpenAI:
# from openai import OpenAI
# client = OpenAI(api_key="SUA_CHAVE_API_OPENAI")
# response = client.chat.completions.create(
# model="gpt-3.5-turbo",
# messages=[
# {"role": "system", "content": "Você é um assistente útil."},
# {"role": "user", "content": llm_prompt}
# ]
# ]
# print(response.choices[0].message.content)
Geração Aumentada por Recuperação (RAG): Este é o segredo do sucesso. Em vez de depender apenas do conhecimento pré-treinado do LLM (que não inclui seus dados SAP específicos), o RAG aprimora as capacidades do LLM, fornecendo-lhe contexto relevante e em tempo real, recuperado do seu banco de dados vetorial. Isso melhora drasticamente a precisão, reduz as "alucinações" e garante que as respostas da IA sejam baseadas nas suas informações SAP reais. Sem o RAG, um LLM apenas adivinharia o status do seu pedido de compra.
Passo 5: Construindo o Fluxo Conversacional e a Interface do Usuário
Com a extração de dados, preparação e integração de LLM em vigor, o próximo passo é juntar tudo em um assistente funcional e interativo. Isso envolve definir a lógica conversacional e apresentá-la através de uma interface do usuário.
O Loop de Lógica Principal:
- Entrada do Usuário: O usuário digita uma pergunta na UI (por exemplo, "Qual o status do PO 4500001234?").
- Embed da Consulta do Usuário: Converta a pergunta do usuário em um embedding vetorial.
- Consulta ao Vector Store: Use este embedding da consulta para buscar em seu banco de dados vetorial os pedaços de dados SAP mais semanticamente semelhantes (por exemplo, os detalhes reais do PO, documentação relevante).
- Combinar Contexto com a Consulta do Usuário: Monte o contexto SAP recuperado e a consulta original do usuário em um prompt bem elaborado para o LLM (conforme mostrado no Passo 4).
- LLM Gera Resposta: Envie o prompt para a API do LLM escolhido. O LLM processa as informações e gera uma resposta em linguagem natural.
- Exibir Resposta: Apresente a resposta do LLM de volta ao usuário através da UI.
Opções Simples de UI para Testes Iniciais:
- Interface de Linha de Comando (CLI): O ponto de partida mais simples. Ótimo para prototipagem rápida e teste da lógica de backend.
# Exemplo muito simplificado while True: user_input = input("Pergunte sobre o SAP (ou 'sair'): ") if user_input.lower() == 'sair': break # ... (chame seu pipeline RAG aqui) ... # response = get_sap_ai_response(user_input) # print(f"Assistente: {response}") - Streamlit: Uma excelente biblioteca Python para criar aplicações web simples e interativas com código mínimo. Perfeito para ferramentas internas e UIs de prova de conceito. Permite construir rapidamente uma interface de chat.
- Flask Web App: Para um pouco mais de controle e personalização, uma aplicação Flask leve pode servir como sua UI web. Isso lhe dá mais flexibilidade no design e na integração.
Enfatize o desenvolvimento iterativo aqui. Faça um CLI básico funcionar primeiro, depois passe para um aplicativo Streamlit simples. Não super-projete a UI nas fases iniciais. O foco deve ser na precisão e utilidade das respostas da IA.
Para proprietários de processos que buscam acelerar o desenvolvimento da UI sem profunda experiência em front-end, considere utilizar uma plataforma low-code como Bubble.io ou Anyscale's Ray para construir a interface conversacional. Embora Ray seja mais para escalonamento de Python, seu ecossistema pode suportar frameworks de UI. Alternativamente, frameworks nativos de Python como Gradio podem criar uma UI para seu LLM em minutos. Essas ferramentas permitem que você se concentre na lógica central da IA, enquanto ainda oferece uma experiência interativa e profissional aos seus usuários, muito mais rápido do que o desenvolvimento web tradicional.
Passo 6: Testes, Refinamento e Otimização de Desempenho
Construir o assistente é apenas metade da batalha; garantir que ele seja preciso, confiável e tenha bom desempenho é igualmente crítico. Este passo é contínuo e iterativo.
Metodologias de Teste:
- Testes Unitários: Teste componentes individuais – seu conector SAP está buscando dados corretamente? Seus embeddings estão sendo gerados? A API do LLM está respondendo?
- Testes de Integração: Teste o fluxo de ponta a ponta. Uma consulta do usuário recupera corretamente o contexto, é processada pelo LLM e retorna uma resposta precisa?
- Testes de Aceitação do Usuário (UAT): Isso é fundamental. Peça a usuários de negócio reais (aqueles cujas perguntas você está tentando responder) para testar o assistente. Forneça a eles um conjunto de perguntas comuns e observe suas interações. Colete seus feedbacks rigorosamente.
Estratégias de Refinamento:
- Expansão/Correção da Base de Conhecimento: Se a IA der uma resposta errada, muitas vezes é porque a informação relevante não estava em sua base de conhecimento ou estava mal estruturada. Adicione mais documentação, corrija pontos de dados ou refine como os dados são divididos em pedaços e incorporados.
- Ajuste da Engenharia de Prompt: Experimente diferentes prompts de sistema, instruções e exemplos de few-shot (fornecendo ao LLM alguns pares de perguntas e respostas de exemplo). Pequenos ajustes nos prompts podem gerar melhorias significativas na precisão.
- Lógica de Extração de Dados: Os dados SAP estão sendo extraídos correta e completamente? Existem casos de borda em que os dados estão faltando ou malformados?
- Seleção do Modelo de Embedding: Se a precisão ainda for um problema, considere experimentar diferentes modelos de embedding. Alguns modelos são mais adequados para domínios específicos.
Otimização de Desempenho:
- Tempo de Resposta: Monitore a rapidez com que o assistente responde. A latência pode vir da extração de dados SAP, buscas no banco de dados vetorial ou chamadas de API do LLM. Otimize cada componente. O cache de dados SAP frequentemente acessados pode ajudar.
- Precisão: Esta é a métrica mais crítica. Defina o que "preciso" significa para seus casos de uso (por exemplo, ele fornece o status correto do PO 95% das vezes?). Acompanhe a precisão ao longo do tempo.
- Tratamento de Erros: Implemente um tratamento robusto de erros para todas as chamadas externas (conexão SAP, API do LLM, banco de dados vetorial). O que acontece se o SAP estiver fora do ar? E se a API do LLM retornar um erro? Forneça mensagens de fallback elegantes ao usuário.
Recomendo configurar um mecanismo de feedback diretamente na sua UI (por exemplo, "Esta resposta foi útil? Sim/Não" com uma caixa de comentários opcional). Isso fornece dados inestimáveis para a melhoria contínua.
Passo 7: Considerações de Implantação e Escalabilidade
Uma vez que seu assistente de IA SAP esteja testado e refinado, é hora de movê-lo de um ambiente de desenvolvimento para um ambiente de produção, onde seus usuários finais poderão se beneficiar dele.
Opções de Implantação:
- Funções Serverless na Nuvem (Recomendado para implantação inicial):
- AWS Lambda, Azure Functions, Google Cloud Run: Esses serviços permitem que você implante seu código Python sem gerenciar servidores. Você paga apenas pelo tempo de computação consumido. Ideal para arquiteturas orientadas a eventos, onde o assistente é invocado sob demanda.
- Prós: Baixa sobrecarga operacional, escalabilidade automática, custo-benefício para uso flutuante.
- Contras: "Cold starts" (latência inicial) podem ser uma preocupação para uso muito infrequente, mas geralmente são insignificantes.
- Containerização (Docker & Kubernetes):
- Docker: Empacote sua aplicação Python e todas as suas dependências em um único contêiner portátil.
- Kubernetes (EKS, AKS, GKE): Orquestre e escale seus contêineres Docker em um cluster de servidores.
- Prós: Alto controle, portabilidade, excelente para arquiteturas complexas baseadas em microsserviços, escalabilidade robusta.
- Contras: Maior complexidade operacional, exige mais expertise em gerenciamento de infraestrutura.
Monitoramento e Registro (Logging):
Você precisa saber o que seu assistente está fazendo em produção. Implemente:
- Monitoramento de Desempenho de Aplicações (APM): Ferramentas como Datadog, New Relic ou AWS CloudWatch/Azure Monitor para rastrear tempos de resposta, erros e utilização de recursos.
- Registro (Logging): Registre consultas de usuários, contexto recuperado, prompts do LLM e respostas. Isso é crítico para depuração, auditoria e melhoria contínua (por exemplo, identificando perguntas comuns não respondidas).
- Alertas: Configure alertas para erros críticos (por exemplo, falhas de conexão SAP, erros de API do LLM, alta latência) para resolver problemas proativamente.
Melhores Práticas de Segurança para Produção:
- Gerenciamento de Credenciais: Use gerenciadores de segredos na nuvem (AWS Secrets Manager, Azure Key Vault, Google Secret Manager) para armazenar credenciais SAP e de API do LLM com segurança. Nunca as codifique diretamente.
- Segurança de Rede: Garanta que o acesso à rede da sua aplicação ao SAP seja restrito (por exemplo, via VPN, links privados, whitelisting de IP).
- Menor Privilégio: A conta de usuário SAP usada pelo seu assistente deve ter apenas as permissões de leitura mínimas necessárias.
- Higienização de Entrada/Saída: Embora os LLMs sejam geralmente robustos, certifique-se de que nenhuma entrada ou saída maliciosa possa comprometer seu sistema.