SAP Datasphere + ChatGPT: Como Criar uma Camada de Análise Self-Service no Brasil
Descubra como construir uma camada de análise self-service usando SAP Datasphere e ChatGPT. Adapte para o contexto brasileiro, otimize custos e empodere usuários de negócios com acesso a dados.

O Problema Silencioso na Análise de Dados SAP
A SAP tem prometido análises self-service há mais de uma década. De consultas BW a Lumira e Analytics Cloud, cada geração de ferramentas fez a mesma promessa: usuários de negócios seriam capazes de responder às suas próprias perguntas sem depender da TI. E cada geração falhou pela mesma razão — as ferramentas ainda exigem que os usuários compreendam o modelo de dados.
Saber que sua receita de vendas está na tabela de fatos ACDOCA com um filtro de data de lançamento em BUDAT, código da empresa em RBUKRS e centro de lucro em PRCTR não é algo que um gerente de vendas regional deveria precisar saber. Ele quer perguntar "quais foram nossos 10 principais clientes por receita no 1º trimestre de 2026 para a região da América Latina?" e obter uma resposta. Não um tutorial sobre como construir uma consulta.
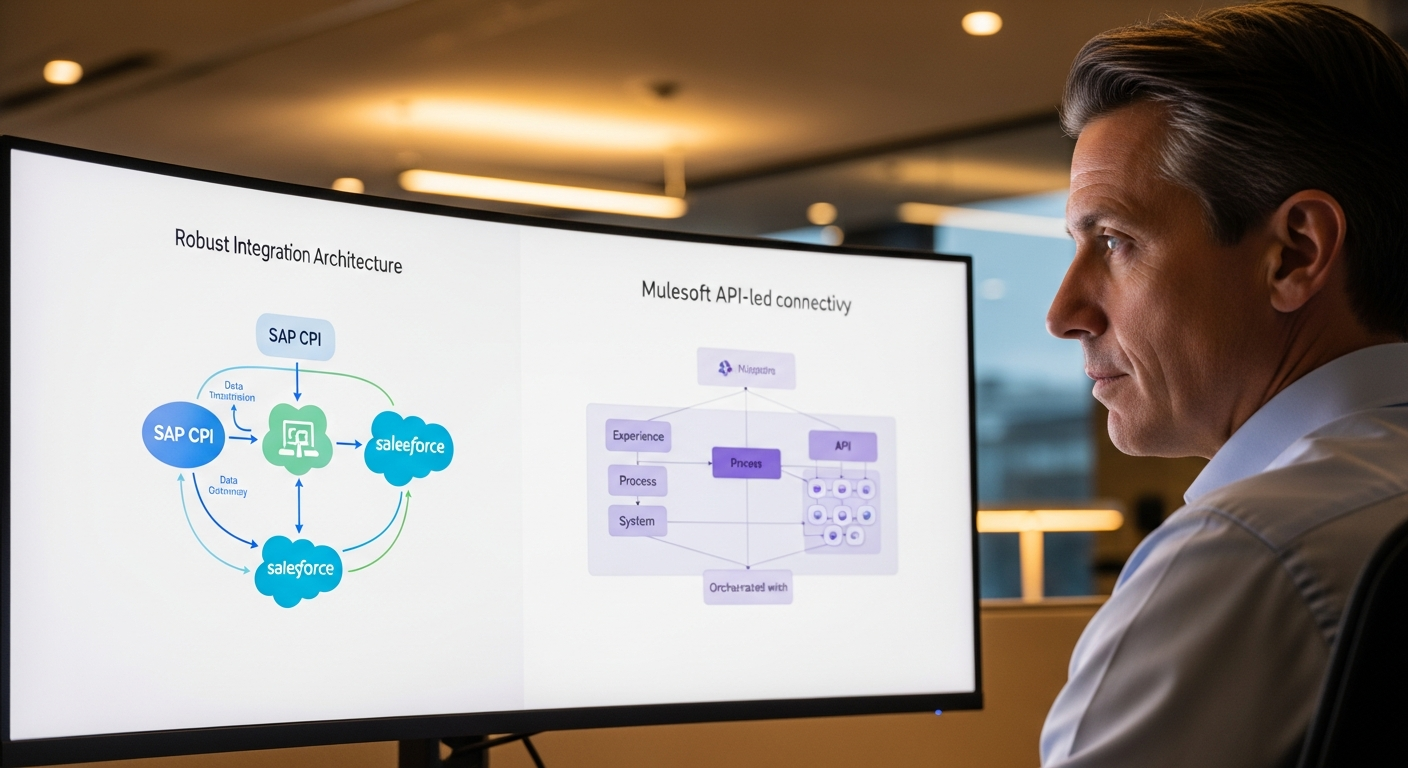
O SAP Datasphere (o antigo Data Warehouse Cloud) realmente melhorou muito o problema da camada de dados. Federação, replicação e a camada de negócios semântica oferecem uma visão unificada de dados SAP e não-SAP. Mas a "última milha" — permitir que usuários não-técnicos consultem esses dados de forma natural — ainda está faltando no produto padrão.
Essa é a lacuna que vamos preencher. Construiremos uma interface de linguagem natural sobre o SAP Datasphere que usa o GPT-4 da OpenAI (via Generative AI Hub do SAP AI Core, ou diretamente) para traduzir perguntas em português simples para consultas SQL, executá-las no Datasphere e retornar resultados formatados. Todo o sistema levou três semanas para ser construído e está em produção desde novembro de 2025.
Visão Geral da Arquitetura
Veja o que estamos construindo:
- SAP Datasphere — a plataforma de dados, contendo dados replicados e federados de S/4HANA, BW/4HANA e fontes externas
- Um serviço de middleware em Python — gerencia a conversação, consulta de metadados e geração de consultas
- OpenAI GPT-4 (ou GPT-4o) — traduz linguagem natural para SQL
- Um frontend web simples — interface estilo chat onde os usuários digitam perguntas
- SAP Analytics Cloud (opcional) — para usuários que desejam visualizar os resultados como gráficos
O truque que faz isso realmente funcionar (ao contrário das dezenas de demonstrações de "converse com seu banco de dados" que desmoronam com dados reais) é a camada de metadados semântica. Não apenas jogamos o esquema de tabela bruto para o GPT-4 e torcemos pelo melhor. Construímos um catálogo de metadados curado que descreve cada tabela e coluna em linguagem de negócios, inclui exemplos de valores válidos, especifica relacionamentos de junção e fornece modelos de consulta para perguntas comuns.
Configurando o SAP Datasphere para Acesso via API
Primeiro, vamos garantir que seu tenant do Datasphere esteja acessível via API. Você precisará:
- Um tenant do SAP Datasphere com a capacidade "Consumption API" habilitada
- Um usuário de banco de dados com acesso de leitura aos seus modelos analíticos
- Os detalhes de conexão ODBC/JDBC das configurações de Acesso ao Banco de Dados do Datasphere
No Datasphere, vá para Gerenciamento de Espaço > seu espaço > Acesso ao Banco de Dados. Crie um usuário de banco de dados se ainda não o fez. Anote o host, a porta e o nome do esquema — você precisará deles para se conectar via Python.
# Detalhes de conexão do Acesso ao Banco de Dados do Datasphere
DSP_HOST = "seu-tenant.hana.prod-eu10.hanacloud.ondemand.com"
DSP_PORT = 443
DSP_USER = "seu_usuario_db"
DSP_PASSWORD = "sua_senha" # Use variáveis de ambiente em produção
DSP_SCHEMA = "seu_esquema_espaco"Para conectividade Python, usamos a biblioteca hdbcli (cliente SAP HANA para Python):
from hdbcli import dbapi
def get_datasphere_connection():
conn = dbapi.connect(
address=DSP_HOST,
port=DSP_PORT,
user=DSP_USER,
password=DSP_PASSWORD,
encrypt=True,
sslValidateCertificate=True
)
return conn
def execute_query(query, params=None):
conn = get_datasphere_connection()
cursor = conn.cursor()
try:
cursor.execute(query, params or [])
columns = [desc[0] for desc in cursor.description]
rows = cursor.fetchall()
return columns, rows
finally:
cursor.close()
conn.close()Construindo a Camada de Metadados Semânticos
Esta é a parte mais importante de todo o sistema. Sem bons metadados, o GPT-4 gerará SQL sintaticamente correto que retorna resultados errados. E resultados errados que parecem certos são muito piores do que uma mensagem de erro.
Crie um arquivo de catálogo de metadados (eu uso YAML, mas JSON também funciona):
# metadata/sales_analytics.yaml
tables:
- name: V_SALES_ORDERS
description: "Dados de pedidos de vendas incluindo detalhes de cabeçalho e item, replicados das tabelas S/4HANA VBAK/VBAP"
business_context: "Contém todos os pedidos de vendas. Use para análise de receita, rastreamento de volume de pedidos e padrões de compra de clientes."
columns:
- name: VBELN
description: "Número do pedido de vendas"
business_name: "Número do Pedido"
data_type: "NVARCHAR(10)"
example_values: ["0000012345", "0000067890"]
- name: ERDAT
description: "Data de criação do pedido"
business_name: "Data do Pedido"
data_type: "DATE"
notes: "Formato AAAA-MM-DD. Para análise trimestral, use QUARTER(ERDAT)"
- name: KUNNR
description: "Número do cliente, chave estrangeira para V_CUSTOMERS"
business_name: "Cliente"
data_type: "NVARCHAR(10)"
join_to: "V_CUSTOMERS.KUNNR"
- name: NETWR
description: "Valor líquido do pedido na moeda do documento"
business_name: "Valor do Pedido"
data_type: "DECIMAL(15,2)"
aggregation: "SOMA para totais, MÉDIA para valor médio do pedido"
notes: "Sempre emparelhe com WAERK (moeda) ao exibir. Para relatórios consolidados, use NETWR_LC (moeda local) ou NETWR_GC (moeda do grupo)"
- name: WAERK
description: "Código da moeda do documento"
business_name: "Moeda"
data_type: "NVARCHAR(5)"
example_values: ["BRL", "USD", "EUR"]
- name: VKORG
description: "Organização de vendas"
business_name: "Org. Vendas"
data_type: "NVARCHAR(4)"
valid_values:
"1000": "Sudeste Brasil"
"2000": "Sul Brasil"
"3000": "Nordeste Brasil"
- name: AUART
description: "Tipo de documento de vendas"
business_name: "Tipo de Pedido"
data_type: "NVARCHAR(4)"
valid_values:
"TA": "Pedido Padrão"
"KE": "Preenchimento Consignação"
"RE": "Devoluções"
- name: NETWR_GC
description: "Valor líquido do pedido na moeda do grupo (BRL)"
business_name: "Valor do Pedido (BRL)"
data_type: "DECIMAL(15,2)"
aggregation: "SOMA para totais. Use para comparações entre regiões"
- name: V_CUSTOMERS
description: "Dados mestre de clientes de KNA1/KNB1"
business_context: "Detalhes do cliente incluindo nome, região, indústria e dados de crédito"
columns:
- name: KUNNR
description: "Número do cliente"
business_name: "Número do Cliente"
data_type: "NVARCHAR(10)"
- name: NAME1
description: "Nome do cliente"
business_name: "Nome do Cliente"
data_type: "NVARCHAR(35)"
- name: LAND1
description: "Código do país"
business_name: "País"
data_type: "NVARCHAR(3)"
- name: BRSCH
description: "Setor da indústria"
business_name: "Indústria"
data_type: "NVARCHAR(4)"
valid_values:
"0001": "Manufatura"
"0002": "Varejo"
"0003": "Serviços"
"0004": "Tecnologia"
common_queries:
- question: "principais clientes por receita"
template: |
SELECT c.NAME1 as customer_name, SUM(s.NETWR_GC) as total_revenue
FROM V_SALES_ORDERS s JOIN V_CUSTOMERS c ON s.KUNNR = c.KUNNR
WHERE s.ERDAT BETWEEN '{start_date}' AND '{end_date}'
AND s.AUART = 'TA'
GROUP BY c.NAME1 ORDER BY total_revenue DESC LIMIT {limit}
- question: "receita por região"
template: |
SELECT s.VKORG as sales_org, SUM(s.NETWR_GC) as revenue
FROM V_SALES_ORDERS s
WHERE s.ERDAT BETWEEN '{start_date}' AND '{end_date}'
AND s.AUART NOT IN ('RE')
GROUP BY s.VKORG ORDER BY revenue DESCObserve quanto contexto estamos fornecendo. Cada coluna tem um nome de negócio, exemplos de valores, mapeamentos de valores válidos e notas sobre como usá-lo corretamente. A seção common_queries fornece ao GPT-4 modelos para perguntas frequentes, reduzindo a chance de erros.
O Motor de Geração de Consultas
Aqui está o núcleo do sistema — o módulo que pega uma pergunta em linguagem natural, a combina com metadados e pede ao GPT-4 para gerar SQL:
import openai
import yaml
import json
class QueryGenerator:
def __init__(self, metadata_path, openai_api_key):
with open(metadata_path) as f:
self.metadata = yaml.safe_load(f)
self.client = openai.OpenAI(api_key=openai_api_key)
self.conversation_history = []
def _build_system_prompt(self):
schema_description = []
for table in self.metadata['tables']:
cols = []
for col in table['columns']:
col_desc = f" - {col['name']} ({col['business_name']}): {col['description']}"
if 'valid_values' in col:
col_desc += f" Valores válidos: {json.dumps(col['valid_values'])}"
if 'notes' in col:
col_desc += f" Nota: {col['notes']}"
cols.append(col_desc)
schema_description.append(
f"Tabela: {table['name']}\n"
f"Descrição: {table['description']}\n"
f"Contexto de negócios: {table['business_context']}\n"
f"Colunas:\n" + "\n".join(cols)
)
common_q = ""
if 'common_queries' in self.metadata:
for q in self.metadata['common_queries']:
common_q += f"\nExemplo - '{q['question']}':\n{q['template']}\n"
return f"""Você é um gerador de consultas SQL para SAP Datasphere (sintaxe HANA SQL).
Você traduz perguntas em linguagem natural para consultas SQL.
REGRAS IMPORTANTES:
1. Use apenas tabelas e colunas do esquema abaixo. Nunca invente colunas.
2. Use a sintaxe HANA SQL (TOP não é suportado, use LIMIT em vez disso).
3. Ao comparar datas, use o formato TO_DATE('AAAA-MM-DD').
4. Sempre exclua devoluções (AUART = 'RE') dos cálculos de receita, a menos que seja solicitado.
5. Use NETWR_GC (moeda do grupo BRL) para comparações entre regiões.
6. Ao perguntar sobre "Q1", "Q2" etc., mapeie para: Q1=Jan-Mar, Q2=Abr-Jun, Q3=Jul-Set, Q4=Out-Dez.
7. Retorne APENAS a consulta SQL, sem explicação.
8. Se a pergunta não puder ser respondida com as tabelas disponíveis, diga "NAO_POSSO_RESPONDER:" seguido de uma explicação.
ESQUEMA:
{chr(10).join(schema_description)}
EXEMPLOS DE CONSULTAS:
{common_q}"""
def generate_query(self, user_question):
if not self.conversation_history:
self.conversation_history.append({
"role": "system",
"content": self._build_system_prompt()
})
self.conversation_history.append({
"role": "user",
"content": user_question
})
response = self.client.chat.completions.create(
model="gpt-4",
messages=self.conversation_history,
temperature=0.1,
max_tokens=500
)
sql = response.choices[0].message.content.strip()
self.conversation_history.append({
"role": "assistant",
"content": sql
})
return sqlValidação e Segurança das Consultas
Você absolutamente não pode executar SQL gerado por IA sem validação. O GPT-4 é bom, mas ocasionalmente gera consultas que varreriam tabelas inteiras, produziriam produtos cartesianos ou (em casos adversários) tentariam modificar dados.
import sqlparse
class QueryValidator:
BLOCKED_KEYWORDS = ['INSERT', 'UPDATE', 'DELETE', 'DROP', 'ALTER',
'CREATE', 'TRUNCATE', 'MERGE', 'GRANT', 'REVOKE']
MAX_RESULT_ROWS = 10000
def __init__(self, allowed_tables):
self.allowed_tables = {t.upper() for t in allowed_tables}
def validate(self, sql):
errors = []
# Verifica tentativas de modificação de dados
parsed = sqlparse.parse(sql)
for statement in parsed:
stmt_type = statement.get_type()
if stmt_type and stmt_type.upper() != 'SELECT':
errors.append(f"Apenas declarações SELECT são permitidas, foi recebido {stmt_type}")
# Verifica palavras-chave bloqueadas
sql_upper = sql.upper()
for keyword in self.BLOCKED_KEYWORDS:
if keyword in sql_upper.split():
errors.append(f"Palavra-chave bloqueada encontrada: {keyword}")
# Extrai nomes de tabelas e valida
tables_used = self._extract_tables(sql)
unauthorized = tables_used - self.allowed_tables
if unauthorized:
errors.append(f"Tabelas não autorizadas: {unauthorized}")
# Garante que a cláusula LIMIT exista
if 'LIMIT' not in sql_upper:
sql = sql.rstrip(';') + f' LIMIT {self.MAX_RESULT_ROWS}'
return errors, sql
def _extract_tables(self, sql):
# Extração simples de tabelas - funciona para padrões comuns
tables = set()
tokens = sql.upper().split()
for i, token in enumerate(tokens):
if token in ('FROM', 'JOIN'):
if i + 1 < len(tokens):
table_name = tokens[i + 1].strip('(),')
if table_name and not table_name.startswith('('):
tables.add(table_name)
return tablesO validador verifica três coisas: nenhuma declaração de modificação de dados, apenas tabelas permitidas e um limite de linhas obrigatório. O usuário de banco de dados que criamos no Datasphere também tem acesso somente leitura, então, mesmo que uma consulta maliciosa de alguma forma passe pela validação, o próprio banco de dados não permitirá modificações.
Construindo a Camada de Conversação
Um sistema de consulta única é útil, mas a análise self-service real exige contexto conversacional. Os usuários querem fazer uma pergunta, ver os resultados e, em seguida, fazer uma pergunta de acompanhamento: "agora detalhe por trimestre" ou "exclua o setor governamental."
class AnalyticsAssistant:
def __init__(self, metadata_path, openai_key, datasphere_config):
self.generator = QueryGenerator(metadata_path, openai_key)
self.validator = QueryValidator(
allowed_tables=[t['name'] for t in self.generator.metadata['tables']]
)
self.dsp_config = datasphere_config
self.query_history = []
def ask(self, question):
# Gera SQL a partir da linguagem natural
sql = self.generator.generate_query(question)
# Verifica se o modelo disse que não pode responder
if sql.startswith('NAO_POSSO_RESPONDER:'):
return {
'status': 'cannot_answer',
'message': sql.replace('NAO_POSSO_RESPONDER:', '').strip(),
'sql': None,
'data': None
}
# Valida o SQL gerado
errors, validated_sql = self.validator.validate(sql)
if errors:
return {
'status': 'validation_error',
'message': f"Falha na validação da consulta: {'; '.join(errors)}",
'sql': sql,
'data': None
}
# Executa no Datasphere
try:
columns, rows = execute_query(validated_sql)
self.query_history.append({
'question': question,
'sql': validated_sql,
'row_count': len(rows)
})
return {
'status': 'success',
'sql': validated_sql,
'columns': columns,
'data': rows,
'row_count': len(rows)
}
except Exception as e:
# Se a consulta falhar, pede ao GPT-4 para corrigi-la
fix_response = self.generator.generate_query(
f"A consulta anterior falhou com o erro: {str(e)}. "
f"Por favor, corrija a consulta SQL para responder à pergunta original."
)
errors2, fixed_sql = self.validator.validate(fix_response)
if not errors2:
try:
columns, rows = execute_query(fixed_sql)
return {
'status': 'success',
'sql': fixed_sql,
'columns': columns,
'data': rows,
'row_count': len(rows),
'note': 'A consulta foi corrigida automaticamente após a falha inicial'
}
except Exception as e2:
pass
return {
'status': 'error',
'message': f"Falha na execução da consulta: {str(e)}",
'sql': validated_sql,
'data': None
}Observe o loop de autocorreção. Quando uma consulta gerada falha (geralmente devido a uma incompatibilidade de nome de coluna ou problema de sintaxe), o sistema envia o erro de volta ao GPT-4 e pede para corrigir a consulta. Em minha experiência, essa autocorreção é bem-sucedida em cerca de 60% das vezes, o que significa que os usuários veem erros com menos frequência.
A Interface Web
O frontend é uma aplicação Flask simples com uma interface estilo chat. Nada sofisticado — o valor está no backend, não na UI:
from flask import Flask, render_template, request, jsonify, session
import uuid
app = Flask(__name__)
app.secret_key = 'sua-chave-secreta'
assistants = {} # session_id -> AnalyticsAssistant
@app.route('/ask', methods=['POST'])
def ask():
session_id = session.get('id')
if not session_id:
session_id = str(uuid.uuid4())
session['id'] = session_id
if session_id not in assistants:
assistants[session_id] = AnalyticsAssistant(
metadata_path='metadata/sales_analytics.yaml',
openai_key=OPENAI_API_KEY,
datasphere_config=DSP_CONFIG
)
question = request.json.get('question', '')
result = assistants[session_id].ask(question)
# Formata a resposta
if result['status'] == 'success':
# Converte para tabela HTML
html_table = format_as_html_table(result['columns'], result['data'])
return jsonify({
'answer': html_table,
'sql': result['sql'],
'row_count': result['row_count'],
'status': 'success'
})
else:
return jsonify({
'answer': result['message'],
'sql': result.get('sql'),
'status': result['status']
})Precisão e Desempenho no Mundo Real
Depois de executar este sistema com 34 usuários ativos nos departamentos de vendas, finanças e cadeia de suprimentos por cinco meses, aqui estão os números reais:
| Métrica | Valor |
|---|---|
| Total de perguntas feitas | 4.847 |
| Consultas bem-sucedidas (resultados corretos) | 3.974 (82%) |
| Consultas autocorreção | 387 (8%) |
| Consultas falhas (usuário notificado) | 486 (10%) |
| Tempo médio de resposta | 3.2 segundos |
| Perguntas por usuário por semana | 7.1 |
| Chamados de TI anteriores para relatórios ad-hoc (mensal) | 45 |
| Chamados de TI atuais para relatórios ad-hoc (mensal) | 8 |
A taxa de precisão de 82% pode parecer baixa, mas o contexto importa. Antes deste sistema, esses 34 usuários tinham que construir suas próprias histórias no SAC (o que a maioria não conseguia fazer) ou enviar chamados de TI e esperar de 3 a 5 dias úteis por uma resposta. A taxa de falha de 10% vem principalmente de perguntas que fazem referência a dados ainda não disponíveis no Datasphere (dados de RH, por exemplo) ou perguntas que são genuinamente ambíguas ("como estamos indo?" não é uma consulta que qualquer sistema possa responder).
Os Tipos de Perguntas que Funcionam Melhor
- Consultas de agregação: "Qual a receita total por organização de vendas no 1º trimestre de 2026?" — 95% de precisão
- Consultas de ranking: "Top 20 clientes por contagem de pedidos este ano" — 93% de precisão
- Consultas de comparação: "Compare a receita do 1º trimestre de 2025 vs 1º trimestre de 2026 por região" — 88% de precisão
- Consultas de filtro: "Mostre todos os pedidos acima de R$ 100 mil de clientes brasileiros" — 91% de precisão
- Consultas de tendência: "Tendência de receita mensal nos últimos 12 meses" — 85% de precisão
- Junções complexas: "Receita por setor de clientes para a região Sudeste" — 78% de precisão
Os Tipos que Apresentam Dificuldade
- Cálculos envolvendo múltiplos passos: "Taxa de crescimento ano a ano por categoria de produto" — 62% de precisão (requer consultas aninhadas)
- Perguntas com referências temporais ambíguas: "Pedidos recentes" — 55% de precisão (quão recente é recente?)
- Perguntas que exigem conhecimento de negócios não presente nos metadados: "Quais clientes estão em risco de churn?" — 40% de precisão (o modelo não conhece sua definição de churn)
Melhorando a Precisão ao Longo do Tempo
A camada de metadados é a principal alavanca para melhorar a precisão. Cada vez que uma consulta falha ou retorna resultados incorretos, analiso a falha e adiciono informações aos metadados:
- Adicione mais exemplos de consultas. Quando os usuários consistentemente fazem perguntas em um padrão com o qual o sistema tem dificuldade, adiciono um modelo à seção common_queries. Isso melhorou a precisão da comparação ano a ano de 62% para 84%.
- Expanda os mapeamentos de valores válidos. Os usuários dizem "Brasil", mas o banco de dados armazena "BR". Adicionar mapeamentos de nome de país para código nos metadados permite que o GPT-4 faça a tradução automaticamente.
- Adicione anotações de regras de negócio. "Receita" deve sempre excluir devoluções (AUART = 'RE') e transferências internas (AUART = 'ZIV'). Documentar isso nos metadados significa que o GPT-4 aplica esses filtros automaticamente.
- Crie definições de visão para padrões complexos. Quando uma pergunta requer uma consulta complexa de múltiplas junções com a qual o GPT-4 tem dificuldade, crie uma visão no Datasphere que pré-junções as tabelas e adicione essa visão aos metadados como uma tabela única e simples.
Análise de Custos
Vamos falar sobre o custo de execução:
- Custos da API OpenAI: Média de 4.800 consultas/mês x ~2.000 tokens por consulta x US$ 0,03/1K tokens (GPT-4) = ~US$ 288/mês. Mudar para GPT-4o reduz isso para ~US$ 48/mês com precisão comparável para geração de SQL.
- SAP Datasphere: Já pago como parte da licença SAP da organização. O custo incremental para o usuário da API é insignificante.
- Infraestrutura: Uma pequena VM para o middleware Python (~US$ 50/mês) e hospedagem para o frontend web (~US$ 20/mês).
- Custo mensal total: ~US$ 120/mês com GPT-4o, ~US$ 360/mês com GPT-4.
Compare isso com o custo de 45 chamados de TI por mês para relatórios ad-hoc. A uma taxa interna de TI de R$ 600/chamado (incluindo tempo de analista, tempo de fila e revisão), isso representa R$ 27.000/mês em mão de obra de TI. O sistema economiza mais de R$ 25.000/mês, enquanto oferece aos usuários respostas instantâneas em vez de uma espera de 3 a 5 dias.
Considerações de Segurança
Conectar um sistema de IA aos seus dados SAP levanta preocupações legítimas de segurança. Veja como lidamos com elas:
- Os dados não vão para a OpenAI. Apenas a pergunta e o esquema de metadados são enviados para a API. Os resultados reais da consulta permanecem dentro da sua rede. O GPT-4 gera SQL; ele nunca vê os dados.
- Segurança em nível de linha. As visões do Datasphere usam privilégios analíticos para restringir dados com base no perfil de autorização do usuário logado. Um gerente de vendas no Sudeste vê apenas dados do Sudeste, mesmo que o SQL gerado não filtre por região.
- Log de auditoria de consultas. Cada pergunta, SQL gerado e tamanho do conjunto de resultados é registrado com a identidade do usuário e o timestamp. Isso cria uma trilha de auditoria completa.
- Sanitização de entrada. O validador SQL impede ataques de injeção, e o usuário do banco de dados tem permissões somente leitura. Mesmo que alguém tente ser inteligente, o pior resultado é uma consulta falha.
Integração com SAP Analytics Cloud
Alguns usuários preferem resultados visuais em vez de tabelas. Para esses usuários, adicionamos uma integração opcional com o SAP Analytics Cloud (SAC). Quando uma consulta retorna dados de série temporal ou categóricos, o sistema pode gerar automaticamente uma história do SAC via API do SAC:
def push_to_sac(columns, data, chart_type='bar'):
# Cria um dataset no SAC
sac_client = SACClient(
tenant_url=SAC_TENANT_URL,
client_id=SAC_CLIENT_ID,
client_secret=SAC_CLIENT_SECRET
)
# Carrega os resultados como um dataset do SAC
dataset_id = sac_client.create_dataset(
name=f"NL_Query_{datetime.now().strftime('%Y%m%d_%H%M%S')}",
columns=columns,
data=data
)
# Gera uma história simples com o gráfico
story_url = sac_client.create_story(
dataset_id=dataset_id,
chart_type=chart_type,
title="Resultado da Consulta Analítica"
)
return story_urlEsta é a parte mais fraca do sistema, honestamente. A API do SAC para criação programática de histórias é limitada, e os resultados parecem genéricos. A maioria dos usuários acaba preferindo as tabelas HTML porque carregam instantaneamente, enquanto a integração com o SAC adiciona de 8 a 10 segundos de latência. Mas para usuários que precisam incorporar resultados em apresentações, ter a opção do SAC é valioso.
Lições de Cinco Meses em Produção
Os metadados nunca estão prontos. Gasto cerca de 2 horas por semana mantendo e expandindo o catálogo de metadados. Novas tabelas são adicionadas ao Datasphere, regras de negócio mudam, usuários fazem perguntas sobre dados que não foram mapeados anteriormente. Este é um trabalho operacional contínuo, não uma configuração única.
Usuários precisam de treinamento para fazer boas perguntas. "Mostre-me tudo" não é uma consulta útil. Realizamos uma sessão de treinamento de 30 minutos mostrando aos usuários como fazer perguntas específicas e respondíveis. A taxa de falha caiu de 18% para 10% após o treinamento.
O GPT-4 é melhor em HANA SQL do que você esperaria. O modelo lida corretamente com funções específicas do HANA como ADD_DAYS, DAYSBETWEEN, ISOWEEK e QUARTER sem prompting especial. Também lida bem com hierarquias e funções de janela, embora os cálculos LAG/LEAD às vezes produzam erros de sintaxe que a autocorreção captura.
O cache de perguntas repetidas economiza dinheiro e tempo. Cerca de 30% das perguntas são variantes da mesma consulta (apenas com diferentes intervalos de datas ou filtros). Uma camada de cache simples que reconhece a similaridade semântica reduziu os custos da API em 25% e o tempo de resposta em 60% para consultas em cache.
Não subestime o valor político. Quando um CFO pode digitar "receita vs. orçamento por centro de custo para o 1º trimestre" e obter uma resposta instantânea durante uma reunião de diretoria, a credibilidade da equipe de dados dispara. Vários de nossos usuários mencionaram especificamente essa capacidade ao defender o orçamento da equipe de dados durante o planejamento anual. O sistema se paga apenas em credibilidade organizacional.
O Que Vem Por Aí
Estamos trabalhando em três melhorias:
- Refinamento de consultas multi-turn com prévia de dados. Mostre as primeiras 5 linhas de resultados e pergunte "isso é o que você esperava?" antes de retornar o conjunto de dados completo. Isso captura problemas de coluna errada e filtro errado precocemente.
- Geração automatizada de metadados. Usando o GPT-4 para ler as definições de tabela do Datasphere e gerar o catálogo inicial de metadados, que é então revisado e corrigido por um humano. Isso reduziria o tempo de configuração para novas tabelas de horas para minutos.
- Entrada de voz via Microsoft Teams. Vários usuários pediram a capacidade de fazer perguntas por voz em reuniões do Teams. Estamos prototipando um bot do Teams que aceita voz, transcreve via Whisper, gera a consulta e retorna os resultados como um cartão do Teams.
O padrão central — linguagem natural enriquecida por metadados para SQL — é aplicável muito além do SAP. Qualquer fonte de dados estruturada com bons metadados pode ser consultada dessa forma. Mas é no SAP que o padrão entrega o maior valor, porque os modelos de dados SAP são notoriamente difíceis para usuários não-técnicos navegarem. Quando você remove essa barreira, a demanda por análises não apenas aumenta — ela muda fundamentalmente quem na organização pode tomar decisões baseadas em dados.