SAP Datasphere + ChatGPT: Construir uma Camada de Análise Self-Service

O Problema de que Ninguém Fala na Analítica SAP
O SAP tem prometido analítica de self-service há mais de uma década. Do BW queries ao Lumira ao Analytics Cloud, cada geração de ferramentas fez a mesma promessa: os utilizadores de negócio conseguirão responder às suas próprias perguntas sem esperar pela TI. E cada geração ficou aquém pela mesma razão — as ferramentas ainda exigem que os utilizadores entendam o modelo de dados.
Saber que a tua receita de vendas vive na tabela de factos ACDOCA com um filtro de data de lançamento em BUDAT, código de sociedade em RBUKRS e centro de lucro em PRCTR não é algo que um gestor de vendas regional precise de saber. Querem perguntar "quais foram os nossos 10 principais clientes por receita no T1 2026 para a região EMEA?" e obter uma resposta. Não um tutorial sobre como construir uma query.
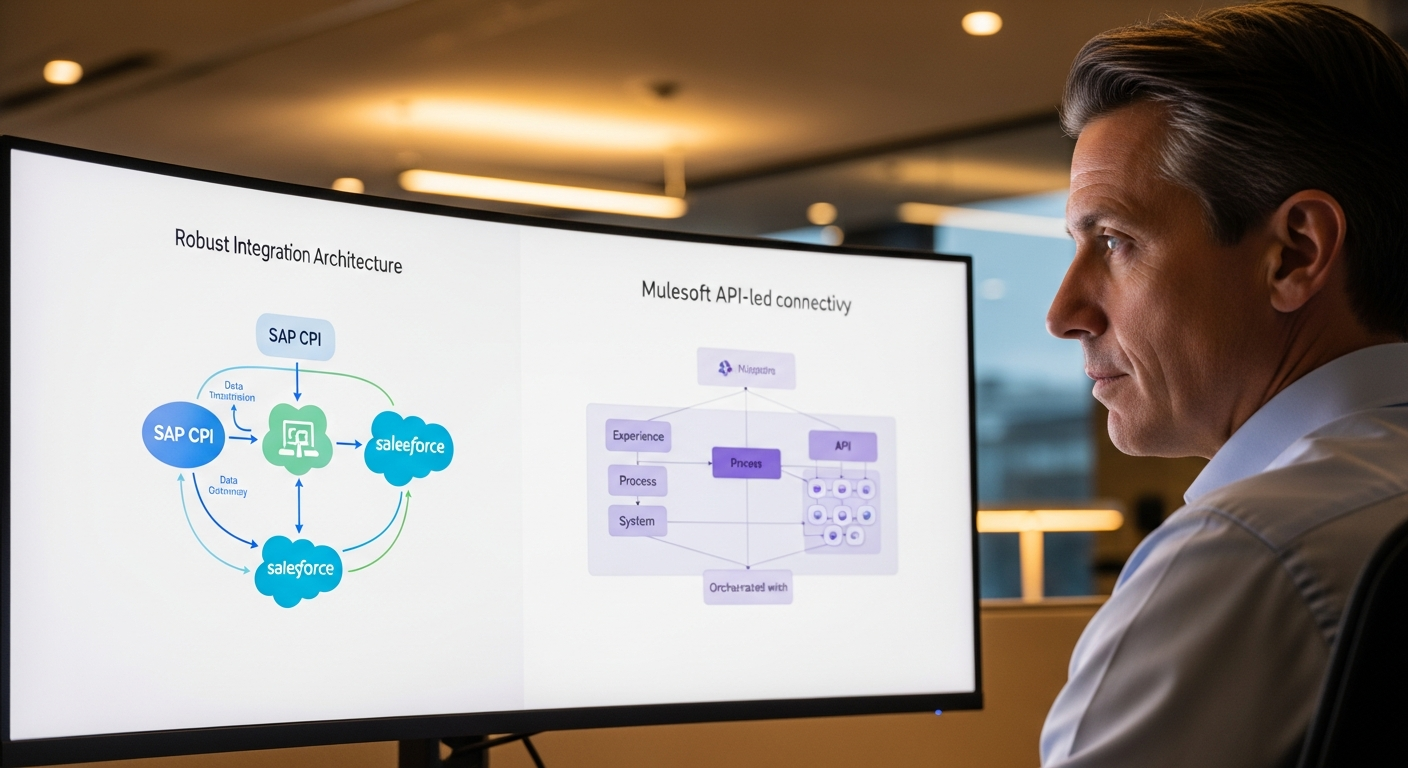
O SAP Datasphere (o antigo Data Warehouse Cloud renomeado) melhorou muito o problema da camada de dados. A federação, replicação e a camada semântica de negócio dão-te uma visão unificada de dados SAP e não-SAP. Mas a última milha — permitir que utilizadores não técnicos consultem esses dados de forma natural — ainda está em falta no produto padrão.
É essa lacuna que vamos preencher. Vamos construir uma interface de linguagem natural sobre o SAP Datasphere que usa o GPT-4 da OpenAI (via SAP AI Core's Generative AI Hub, ou directamente) para traduzir perguntas em inglês simples para queries SQL, executá-las contra o Datasphere e devolver resultados formatados. O sistema completo demorou três semanas a construir e está em produção desde Novembro de 2025.
Visão Geral da Arquitectura
Isto é o que estamos a construir:
- SAP Datasphere — a plataforma de dados, contendo dados replicados e federados do S/4HANA, BW/4HANA e fontes externas
- Um serviço de middleware Python — gere a conversa, a pesquisa de metadados e a geração de queries
- OpenAI GPT-4 (ou GPT-4o) — traduz linguagem natural para SQL
- Um frontend web simples — interface estilo chat onde os utilizadores escrevem perguntas
- SAP Analytics Cloud (opcional) — para utilizadores que querem visualizar os resultados como gráficos
O truque que faz isto realmente funcionar (em vez dos dezenas de demos "conversa com a tua base de dados" que se desfazem com dados reais) é a camada de metadados semânticos. Não jogamos apenas o esquema de tabela em bruto ao GPT-4 e esperamos o melhor. Construímos um catálogo de metadados curado que descreve cada tabela e coluna em linguagem de negócio, inclui exemplos de valores válidos, especifica relações de join e fornece templates de query para perguntas frequentes.
Configurar o SAP Datasphere para Acesso por API
Primeiro, vamos garantir que o teu tenant Datasphere está acessível via API. Precisarás de:
- Um tenant SAP Datasphere com a capacidade "Consumption API" activada
- Um utilizador de base de dados com acesso de leitura aos teus modelos analíticos
- Os detalhes de ligação ODBC/JDBC das definições de Database Access do Datasphere
No Datasphere, vai a Space Management > o teu espaço > Database Access. Cria um utilizador de base de dados se ainda não o fizeste. Anota o host, porto e nome do schema — precisarás deles para ligar do Python.
# Connection details from Datasphere Database Access
DSP_HOST = "your-tenant.hana.prod-eu10.hanacloud.ondemand.com"
DSP_PORT = 443
DSP_USER = "your_db_user"
DSP_PASSWORD = "your_password" # Use environment variables in production
DSP_SCHEMA = "your_space_schema"Para conectividade Python, usamos a biblioteca hdbcli (cliente SAP HANA para Python):
from hdbcli import dbapi
def get_datasphere_connection():
conn = dbapi.connect(
address=DSP_HOST,
port=DSP_PORT,
user=DSP_USER,
password=DSP_PASSWORD,
encrypt=True,
sslValidateCertificate=True
)
return conn
def execute_query(query, params=None):
conn = get_datasphere_connection()
cursor = conn.cursor()
try:
cursor.execute(query, params or [])
columns = [desc[0] for desc in cursor.description]
rows = cursor.fetchall()
return columns, rows
finally:
cursor.close()
conn.close()Construir a Camada de Metadados Semânticos
Esta é a parte mais importante de todo o sistema. Sem bons metadados, o GPT-4 gerará SQL sintaticamente correcto que devolve resultados errados. E resultados errados que parecem correctos são muito piores do que uma mensagem de erro.
Cria um ficheiro de catálogo de metadados (uso YAML, mas JSON também funciona):
# metadata/sales_analytics.yaml
tables:
- name: V_SALES_ORDERS
description: "Sales order data including header and item details, replicated from S/4HANA tables VBAK/VBAP"
business_context: "Contains all sales orders. Use this for revenue analysis, order volume tracking, and customer purchasing patterns."
columns:
- name: VBELN
description: "Sales order number"
business_name: "Order Number"
data_type: "NVARCHAR(10)"
example_values: ["0000012345", "0000067890"]
- name: ERDAT
description: "Date the order was created"
business_name: "Order Date"
data_type: "DATE"
notes: "Format YYYY-MM-DD. For quarterly analysis, use QUARTER(ERDAT)"
- name: KUNNR
description: "Customer number, foreign key to V_CUSTOMERS"
business_name: "Customer"
data_type: "NVARCHAR(10)"
join_to: "V_CUSTOMERS.KUNNR"
- name: NETWR
description: "Net order value in document currency"
business_name: "Order Value"
data_type: "DECIMAL(15,2)"
aggregation: "SUM for totals, AVG for average order value"
notes: "Always pair with WAERK (currency) when displaying. For consolidated reporting, use NETWR_LC (local currency) or NETWR_GC (group currency)"
- name: WAERK
description: "Document currency code"
business_name: "Currency"
data_type: "NVARCHAR(5)"
example_values: ["EUR", "USD", "GBP"]
- name: VKORG
description: "Sales organization"
business_name: "Sales Org"
data_type: "NVARCHAR(4)"
valid_values:
"1000": "EMEA"
"2000": "Americas"
"3000": "APAC"
- name: AUART
description: "Sales document type"
business_name: "Order Type"
data_type: "NVARCHAR(4)"
valid_values:
"TA": "Standard Order"
"KE": "Consignment Fill-up"
"RE": "Returns"
- name: NETWR_GC
description: "Net order value in group currency (EUR)"
business_name: "Order Value (EUR)"
data_type: "DECIMAL(15,2)"
aggregation: "SUM for totals. Use this for cross-region comparisons"
- name: V_CUSTOMERS
description: "Customer master data from KNA1/KNB1"
business_context: "Customer details including name, region, industry, and credit data"
columns:
- name: KUNNR
description: "Customer number"
business_name: "Customer Number"
data_type: "NVARCHAR(10)"
- name: NAME1
description: "Customer name"
business_name: "Customer Name"
data_type: "NVARCHAR(35)"
- name: LAND1
description: "Country code"
business_name: "Country"
data_type: "NVARCHAR(3)"
- name: BRSCH
description: "Industry sector code"
business_name: "Industry"
data_type: "NVARCHAR(4)"
valid_values:
"0001": "Manufacturing"
"0002": "Retail"
"0003": "Services"
"0004": "Technology"
common_queries:
- question: "top customers by revenue"
template: |
SELECT c.NAME1 as customer_name, SUM(s.NETWR_GC) as total_revenue
FROM V_SALES_ORDERS s JOIN V_CUSTOMERS c ON s.KUNNR = c.KUNNR
WHERE s.ERDAT BETWEEN '{start_date}' AND '{end_date}'
AND s.AUART = 'TA'
GROUP BY c.NAME1 ORDER BY total_revenue DESC LIMIT {limit}
- question: "revenue by region"
template: |
SELECT s.VKORG as sales_org, SUM(s.NETWR_GC) as revenue
FROM V_SALES_ORDERS s
WHERE s.ERDAT BETWEEN '{start_date}' AND '{end_date}'
AND s.AUART NOT IN ('RE')
GROUP BY s.VKORG ORDER BY revenue DESCRepara na quantidade de contexto que estamos a fornecer. Cada coluna tem um nome de negócio, exemplos de valores, mapeamentos de valores válidos e notas sobre como a usar correctamente. A secção common_queries dá ao GPT-4 templates para perguntas frequentes, reduzindo a probabilidade de erros.
O Motor de Geração de Queries
Aqui está o núcleo do sistema — o módulo que recebe uma pergunta em linguagem natural, combina-a com os metadados e pede ao GPT-4 que gere SQL:
import openai
import yaml
import json
class QueryGenerator:
def __init__(self, metadata_path, openai_api_key):
with open(metadata_path) as f:
self.metadata = yaml.safe_load(f)
self.client = openai.OpenAI(api_key=openai_api_key)
self.conversation_history = []
def _build_system_prompt(self):
schema_description = []
for table in self.metadata['tables']:
cols = []
for col in table['columns']:
col_desc = f" - {col['name']} ({col['business_name']}): {col['description']}"
if 'valid_values' in col:
col_desc += f" Valid values: {json.dumps(col['valid_values'])}"
if 'notes' in col:
col_desc += f" Note: {col['notes']}"
cols.append(col_desc)
schema_description.append(
f"Table: {table['name']}\n"
f"Description: {table['description']}\n"
f"Business context: {table['business_context']}\n"
f"Columns:\n" + "\n".join(cols)
)
common_q = ""
if 'common_queries' in self.metadata:
for q in self.metadata['common_queries']:
common_q += f"\nExample - '{q['question']}':\n{q['template']}\n"
return f"""You are a SQL query generator for SAP Datasphere (HANA SQL syntax).
You translate natural language questions into SQL queries.
IMPORTANT RULES:
1. Only use tables and columns from the schema below. Never invent columns.
2. Use HANA SQL syntax (TOP is not supported, use LIMIT instead).
3. When comparing dates, use TO_DATE('YYYY-MM-DD') format.
4. Always exclude returns (AUART = 'RE') from revenue calculations unless asked.
5. Use NETWR_GC (group currency EUR) for cross-region comparisons.
6. When asked about "Q1", "Q2" etc., map to: Q1=Jan-Mar, Q2=Apr-Jun, Q3=Jul-Sep, Q4=Oct-Dec.
7. Return ONLY the SQL query, no explanation.
8. If the question cannot be answered with available tables, say "CANNOT_ANSWER:" followed by explanation.
SCHEMA:
{chr(10).join(schema_description)}
EXAMPLE QUERIES:
{common_q}"""
def generate_query(self, user_question):
if not self.conversation_history:
self.conversation_history.append({
"role": "system",
"content": self._build_system_prompt()
})
self.conversation_history.append({
"role": "user",
"content": user_question
})
response = self.client.chat.completions.create(
model="gpt-4",
messages=self.conversation_history,
temperature=0.1,
max_tokens=500
)
sql = response.choices[0].message.content.strip()
self.conversation_history.append({
"role": "assistant",
"content": sql
})
return sqlValidação e Segurança de Queries
Não podes absolutamente executar SQL gerado por IA sem validação. O GPT-4 é bom, mas ocasionalmente gera queries que fariam scan de tabelas inteiras, produziriam produtos cartesianos, ou (em casos adversariais) tentariam modificar dados.
import sqlparse
class QueryValidator:
BLOCKED_KEYWORDS = ['INSERT', 'UPDATE', 'DELETE', 'DROP', 'ALTER',
'CREATE', 'TRUNCATE', 'MERGE', 'GRANT', 'REVOKE']
MAX_RESULT_ROWS = 10000
def __init__(self, allowed_tables):
self.allowed_tables = {t.upper() for t in allowed_tables}
def validate(self, sql):
errors = []
# Check for data modification attempts
parsed = sqlparse.parse(sql)
for statement in parsed:
stmt_type = statement.get_type()
if stmt_type and stmt_type.upper() != 'SELECT':
errors.append(f"Only SELECT statements are allowed, got {stmt_type}")
# Check for blocked keywords
sql_upper = sql.upper()
for keyword in self.BLOCKED_KEYWORDS:
if keyword in sql_upper.split():
errors.append(f"Blocked keyword found: {keyword}")
# Extract table names and validate
tables_used = self._extract_tables(sql)
unauthorized = tables_used - self.allowed_tables
if unauthorized:
errors.append(f"Unauthorized tables: {unauthorized}")
# Ensure LIMIT clause exists
if 'LIMIT' not in sql_upper:
sql = sql.rstrip(';') + f' LIMIT {self.MAX_RESULT_ROWS}'
return errors, sql
def _extract_tables(self, sql):
# Simple table extraction - works for common patterns
tables = set()
tokens = sql.upper().split()
for i, token in enumerate(tokens):
if token in ('FROM', 'JOIN'):
if i + 1 < len(tokens):
table_name = tokens[i + 1].strip('(),')
if table_name and not table_name.startswith('('):
tables.add(table_name)
return tablesO validador verifica três coisas: sem instruções de modificação de dados, apenas tabelas da lista autorizada e um limite de linhas obrigatório. O utilizador de base de dados que criámos no Datasphere também tem acesso apenas de leitura, pelo que mesmo que uma query maliciosa passe de alguma forma a validação, a própria base de dados não permitirá modificações.
Construir a Camada de Conversa
Um sistema de query única é útil, mas a analítica de self-service real requer contexto conversacional. Os utilizadores querem fazer uma pergunta, ver os resultados e depois fazer uma pergunta de seguimento: "agora divide isso por trimestre" ou "exclui o sector governamental."
class AnalyticsAssistant:
def __init__(self, metadata_path, openai_key, datasphere_config):
self.generator = QueryGenerator(metadata_path, openai_key)
self.validator = QueryValidator(
allowed_tables=[t['name'] for t in self.generator.metadata['tables']]
)
self.dsp_config = datasphere_config
self.query_history = []
def ask(self, question):
# Generate SQL from natural language
sql = self.generator.generate_query(question)
# Check if the model said it can't answer
if sql.startswith('CANNOT_ANSWER:'):
return {
'status': 'cannot_answer',
'message': sql.replace('CANNOT_ANSWER:', '').strip(),
'sql': None,
'data': None
}
# Validate the generated SQL
errors, validated_sql = self.validator.validate(sql)
if errors:
return {
'status': 'validation_error',
'message': f"Query validation failed: {'; '.join(errors)}",
'sql': sql,
'data': None
}
# Execute against Datasphere
try:
columns, rows = execute_query(validated_sql)
self.query_history.append({
'question': question,
'sql': validated_sql,
'row_count': len(rows)
})
return {
'status': 'success',
'sql': validated_sql,
'columns': columns,
'data': rows,
'row_count': len(rows)
}
except Exception as e:
# If query fails, ask GPT-4 to fix it
fix_response = self.generator.generate_query(
f"The previous query failed with error: {str(e)}. "
f"Please fix the SQL query to answer the original question."
)
errors2, fixed_sql = self.validator.validate(fix_response)
if not errors2:
try:
columns, rows = execute_query(fixed_sql)
return {
'status': 'success',
'sql': fixed_sql,
'columns': columns,
'data': rows,
'row_count': len(rows),
'note': 'Query was auto-corrected after initial failure'
}
except Exception as e2:
pass
return {
'status': 'error',
'message': f"Query execution failed: {str(e)}",
'sql': validated_sql,
'data': None
}Repara no ciclo de auto-correcção. Quando uma query gerada falha (geralmente devido a um nome de coluna incorrecto ou problema de sintaxe), o sistema envia o erro de volta ao GPT-4 e pede-lhe que corrija a query. Na minha experiência, esta auto-correcção tem sucesso cerca de 60% das vezes, o que significa que os utilizadores vêem erros com menos frequência.
A Interface Web
O frontend é uma aplicação Flask simples com uma interface estilo chat. Nada de sofisticado — o valor está no backend, não na UI:
from flask import Flask, render_template, request, jsonify, session
import uuid
app = Flask(__name__)
app.secret_key = 'your-secret-key'
assistants = {} # session_id -> AnalyticsAssistant
@app.route('/ask', methods=['POST'])
def ask():
session_id = session.get('id')
if not session_id:
session_id = str(uuid.uuid4())
session['id'] = session_id
if session_id not in assistants:
assistants[session_id] = AnalyticsAssistant(
metadata_path='metadata/sales_analytics.yaml',
openai_key=OPENAI_API_KEY,
datasphere_config=DSP_CONFIG
)
question = request.json.get('question', '')
result = assistants[session_id].ask(question)
# Format the response
if result['status'] == 'success':
# Convert to HTML table
html_table = format_as_html_table(result['columns'], result['data'])
return jsonify({
'answer': html_table,
'sql': result['sql'],
'row_count': result['row_count'],
'status': 'success'
})
else:
return jsonify({
'answer': result['message'],
'sql': result.get('sql'),
'status': result['status']
})Precisão e Desempenho no Mundo Real
Após correr este sistema com 34 utilizadores activos nos departamentos de vendas, finanças e cadeia de abastecimento durante cinco meses, estes são os números reais:
| Métrica | Valor |
|---|---|
| Total de perguntas feitas | 4.847 |
| Queries com sucesso (resultados correctos) | 3.974 (82%) |
| Queries auto-corrigidas | 387 (8%) |
| Queries falhadas (utilizador notificado) | 486 (10%) |
| Tempo médio de resposta | 3,2 segundos |
| Perguntas por utilizador por semana | 7,1 |
| Tickets TI anteriores para relatórios ad-hoc (mensal) | 45 |
| Tickets TI actuais para relatórios ad-hoc (mensal) | 8 |
A taxa de precisão de 82% pode parecer baixa, mas o contexto importa. Antes deste sistema, esses 34 utilizadores tinham de ou construir as suas próprias histórias SAC (o que a maioria não conseguia fazer) ou submeter tickets TI e aguardar 3-5 dias úteis por uma resposta. A taxa de falha de 10% vem principalmente de perguntas que fazem referência a dados ainda não disponíveis no Datasphere (dados de RH, por exemplo) ou perguntas genuinamente ambíguas ("como estamos a ir?" não é uma query que qualquer sistema possa responder).
Os Tipos de Perguntas que Funcionam Melhor
- Queries de agregação: "Qual é a receita total por organização de vendas no T1 2026?" — 95% de precisão
- Queries de ranking: "Os 20 principais clientes por volume de pedidos este ano" — 93% de precisão
- Queries de comparação: "Comparar receita do T1 2025 vs T1 2026 por região" — 88% de precisão
- Queries de filtragem: "Mostrar todos os pedidos acima de €100K de clientes alemães" — 91% de precisão
- Queries de tendência: "Tendência de receita mensal dos últimos 12 meses" — 85% de precisão
- Joins complexos: "Receita por sector de clientes para a região APAC" — 78% de precisão
Os Tipos que Têm Dificuldade
- Cálculos envolvendo múltiplos passos: "Taxa de crescimento ano-a-ano por categoria de produto" — 62% de precisão (requer queries aninhadas)
- Perguntas com referências temporais ambíguas: "Pedidos recentes" — 55% de precisão (quão recente é recente?)
- Perguntas que requerem conhecimento de negócio não presente nos metadados: "Quais clientes estão em risco de churn?" — 40% de precisão (o modelo não conhece a tua definição de churn)
Melhorar a Precisão ao Longo do Tempo
A camada de metadados é a principal alavanca para melhorar a precisão. Cada vez que uma query falha ou devolve resultados incorrectos, analiso a falha e adiciono informação aos metadados:
- Adicionar mais queries de exemplo. Quando os utilizadores fazem consistentemente perguntas num padrão com que o sistema tem dificuldade, adiciono um template à secção common_queries. Isto melhorou a precisão das comparações ano-a-ano de 62% para 84%.
- Expandir mapeamentos de valores válidos. Os utilizadores dizem "Alemanha" mas a base de dados armazena "DE". Adicionar mapeamentos nome-de-país-para-código nos metadados permite ao GPT-4 fazer a tradução automaticamente.
- Adicionar anotações de regras de negócio. "Receita" deve sempre excluir devoluções (AUART = 'RE') e transferências internas (AUART = 'ZIV'). Documentar isto nos metadados significa que o GPT-4 aplica estes filtros automaticamente.
- Criar definições de view para padrões complexos. Quando uma pergunta requer uma query complexa de multi-join com que o GPT-4 tem dificuldade, criar uma view no Datasphere que pré-une as tabelas e adicionar essa view aos metadados como uma tabela única e simples.
Análise de Custos
Vamos falar sobre o que isto custa a executar:
- Custos da API OpenAI: Média de 4.800 queries/mês x ~2.000 tokens por query x $0,03/1K tokens (GPT-4) = ~$288/mês. Mudar para GPT-4o baixa isto para ~$48/mês com precisão comparável para geração de SQL.
- SAP Datasphere: Já pago como parte da licença SAP da organização. O custo incremental para o utilizador API é negligenciável.
- Infra-estrutura: Uma VM pequena para o middleware Python (~$50/mês) e hosting para o frontend web (~$20/mês).
- Custo mensal total: ~$120/mês com GPT-4o, ~$360/mês com GPT-4.
Compara isto com o custo de 45 tickets TI por mês para relatórios ad-hoc. A uma taxa TI interna de $120/ticket (incluindo tempo de analista, tempo de fila e revisão), isso são $5.400/mês em mão-de-obra TI. O sistema poupa mais de $5.000/mês enquanto dá aos utilizadores respostas instantâneas em vez de uma espera de 3-5 dias.
Considerações de Segurança
Ligar um sistema de IA aos teus dados SAP levanta preocupações de segurança legítimas. Veja como as tratamos:
- Os dados não vão para a OpenAI. Apenas a pergunta e o esquema de metadados são enviados para a API. Os resultados reais da query ficam dentro da tua rede. O GPT-4 gera SQL; nunca vê os dados.
- Segurança ao nível da linha. As views do Datasphere usam privilégios analíticos para restringir dados com base no perfil de autorização do utilizador com sessão iniciada. Um gestor de vendas na EMEA só vê dados EMEA, mesmo que o SQL gerado não filtre por região.
- Registo de auditoria de queries. Cada pergunta, SQL gerado e tamanho do conjunto de resultados é registado com a identidade do utilizador e timestamp. Isto cria um rasto de auditoria completo.
- Sanitização de input. O validador SQL previne ataques de injecção, e o utilizador de base de dados tem permissões só de leitura. Mesmo que alguém tente ser esperto, o pior resultado é uma query falhada.
Integração com o SAP Analytics Cloud
Alguns utilizadores preferem resultados visuais em vez de tabelas. Para estes utilizadores, adicionámos uma integração opcional com o SAP Analytics Cloud (SAC). Quando uma query devolve dados de série temporal ou categóricos, o sistema pode gerar automaticamente uma história SAC via a API SAC:
def push_to_sac(columns, data, chart_type='bar'):
# Create a dataset in SAC
sac_client = SACClient(
tenant_url=SAC_TENANT_URL,
client_id=SAC_CLIENT_ID,
client_secret=SAC_CLIENT_SECRET
)
# Upload results as a SAC dataset
dataset_id = sac_client.create_dataset(
name=f"NL_Query_{datetime.now().strftime('%Y%m%d_%H%M%S')}",
columns=columns,
data=data
)
# Generate a simple story with the chart
story_url = sac_client.create_story(
dataset_id=dataset_id,
chart_type=chart_type,
title="Analytics Query Result"
)
return story_urlEsta é honestamente a parte mais fraca do sistema. A API SAC para criação programática de histórias é limitada, e os resultados parecem genéricos. A maioria dos utilizadores acaba por preferir as tabelas HTML porque carregam instantaneamente, enquanto a integração SAC adiciona 8-10 segundos de latência. Mas para utilizadores que precisam de incorporar resultados em apresentações, ter a opção SAC é valioso.
Lições de Cinco Meses em Produção
Os metadados nunca estão terminados. Passo cerca de 2 horas por semana a manter e expandir o catálogo de metadados. Novas tabelas são adicionadas ao Datasphere, as regras de negócio mudam, os utilizadores fazem perguntas sobre dados que não estavam previamente mapeados. Este é trabalho operacional contínuo, não uma configuração única.
Os utilizadores precisam de treino para fazer boas perguntas. "Mostra-me tudo" não é uma query útil. Fizemos uma sessão de treino de 30 minutos mostrando aos utilizadores como fazer perguntas específicas e respondíveis. A taxa de falha desceu de 18% para 10% após o treino.
O GPT-4 é melhor em HANA SQL do que esperarias. O modelo trata correctamente funções específicas do HANA como ADD_DAYS, DAYSBETWEEN, ISOWEEK e QUARTER sem prompting especial. Também trata bem hierarquias e funções de janela, embora os cálculos LAG/LEAD às vezes produzam erros de sintaxe que a auto-correcção captura.
Cachear perguntas repetidas poupa dinheiro e tempo. Cerca de 30% das perguntas são variantes da mesma query (apenas com intervalos de datas ou filtros diferentes). Uma camada de cache simples que reconhece semelhança semântica reduziu os custos da API em 25% e o tempo de resposta em 60% para queries em cache.
Não subestimes o valor político. Quando um CFO consegue escrever "receita vs orçamento por centro de custo para o T1" e obter uma resposta instantânea durante uma reunião de conselho, a credibilidade da equipa de dados dispara. Vários dos nossos utilizadores mencionaram especificamente esta capacidade ao defender o orçamento da equipa de dados durante o planeamento anual. O sistema paga-se a si próprio em credibilidade organizacional.
O que Vem a Seguir
Estamos a trabalhar em três melhorias:
- Refinamento de query multi-turno com pré-visualização de dados. Mostrar as primeiras 5 linhas de resultados e perguntar "é isto o que esperavas?" antes de devolver o conjunto de dados completo. Isto apanha problemas de coluna errada e filtro errado cedo.
- Geração automática de metadados. Usar o GPT-4 para ler definições de tabelas do Datasphere e gerar o catálogo de metadados inicial, que é depois revisto e corrigido por um humano. Isto reduziria o tempo de configuração para novas tabelas de horas para minutos.
- Input por voz via Microsoft Teams. Vários utilizadores pediram a capacidade de fazer perguntas por voz em reuniões Teams. Estamos a prototipar um bot Teams que aceita voz, transcreve via Whisper, gera a query e devolve resultados como um cartão Teams.
O padrão central — linguagem natural enriquecida com metadados para SQL — é aplicável muito além do SAP. Qualquer fonte de dados estruturada com bons metadados pode ser consultada desta forma. Mas o SAP é onde o padrão entrega mais valor porque os modelos de dados SAP são notoriamente difíceis de navegar para utilizadores não técnicos. Quando removes essa barreira, a procura por analítica não aumenta apenas — muda fundamentalmente quem na organização pode tomar decisões baseadas em dados.